Home
Articles
Topics
About Me
Steal My Code
Search
Reach out and say, Hi!
Search for Blog
Tags
PowerShell
PSReadLine
PSStyle
Active Directory
Community
CIM-WMI
Jumpstarts
Azure
Windows Services
Azure DevOps
Secret Management
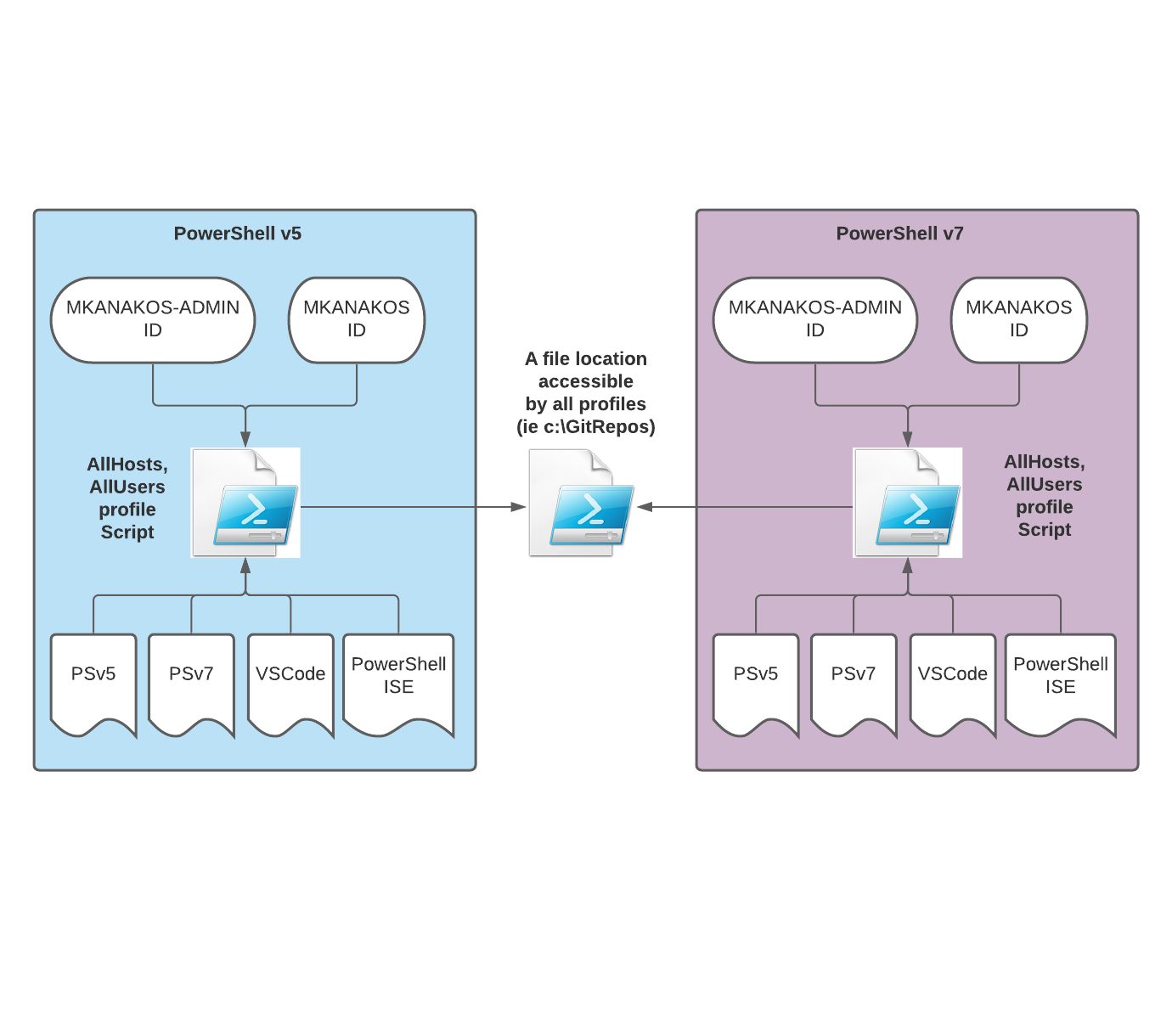
PowerShell Profiles
Windows Terminal
PowerShell Remoting
Group Policy
Event Logs
Server Admin